.svg "Cognidox logo")

What does it mean to 'control documents'? And who needs a formal document control system to manage and optimis...

What does it mean to 'control documents'? And who needs a formal document control system to manage and optimis...

Managing deviations from standard operational procedures is critical to product quality and regulatory complia...

The Cognidox team is delighted to announce we will be hosting CogniCon 24 on 16 May 2024. This is a networking...

Google Drive is a cloud-based program that allows you to create, edit, store, and share documents. Many busine...

ICH Q8 R2 are international guidelines for ensuring Quality by Design in pharmaceutical development. Here’s wh...

How do you log and deal with non-conformities so that faulty products don't end up in the hands of customers? ...

A Trial Master File (TMF) is a comprehensive collection of documents that ensures the conduct of your clinical...

Data integrity is central to the safe development and manufacturing of every life-science product on the marke...

Navigating the complexities of ISO 13485:2016 can seem daunting, but understanding its requirements is crucial...

What is the medical device technical file? What should it contain and how should it be structured? And is it e...

The case for ditching paper based QMS (Quality Management Systems) can seem like a no-brainer. But faced with ...

In 2008, the ICH Q10 Pharmaceutical Quality System (PQS) guidelines introduced a comprehensive model for an ef...

Cognidox and Qualio are both digital quality management systems (QMS) with a focus on the life science and med...

In medical device development, two critical stages of the design process are often confused: design verificati...

What if you could gain approval to sell your medical devices anywhere in the world, by completing a single, re...

What’s the cost of quality? Can it, like QM guru Philip Crosby argued, really be free? Like most things in bus...

Controlling and documenting IQ, OQ and PQ effectively is a complex and time-consuming process for life science...

Medical device audits can be a source of stress for developers and manufacturers. But what exactly are the aud...

Cognidox are delighted to announce the release of our new DocuSign e-signature integration. The new plug in is...

Post-Brexit there has been some confusion about the future use of UKCA (UK Conformity Assessed) markings and w...

Change control in life science development is critical to ensuring the safety of patients. Having a formal pro...

Chip designs are becoming more complex and expensive to develop, verify and validate. Opportunities for fables...

Clinical research demands strict GCP (Good Clinical Practice) compliance. But many institutions stuck with out...

At last! It’s happened! The FDA has announced the date for the publication of its new Quality Management Syste...

Transferring design to production is a process that can be fraught with risk for medical device developers. Ho...
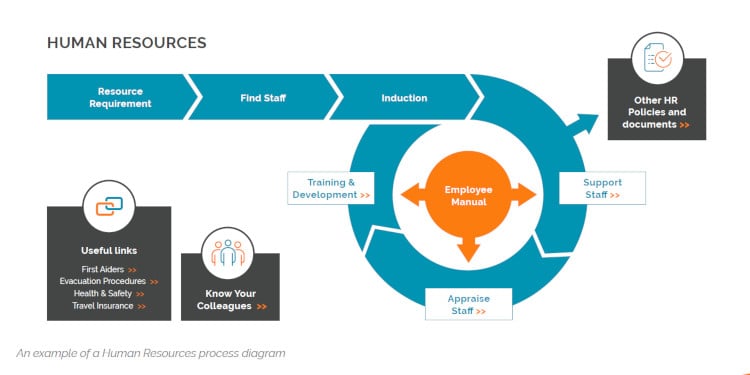
There are many reasons why organisations need to document their SOPs. From ensuring uniformity in end products...

There’s plenty of document management and file-sharing software available on the market, but not all of it is ...

Of all the quality management ‘gurus’, the late Philip Crosby is one of the most readable. In his book ‘Qualit...

The regulations and literature surrounding medical device development are packed with acronyms and technical t...

Will a phase gate process hold back or enhance your new product development? What are the pros and cons of sta...

A Quality Management System (QMS) is a requirement for medical device developers across the globe. But should ...

How can you help your business evolve its mindset to achieve the most instinctive, frictionless and effective ...

Dropbox is an easy to use cloud storage and sync application that is increasingly used in work settings for fi...

The FDA’s Quality System Regulation (QSR) for medical device manufacturers is commonly known as FDA 21 CFR Par...

The medical device development process is typically broken down into five distinct phases. Each one requires i...

It’s the job of your corrective action process to identify and eliminate the systemic issues that will prevent...

SMEs creating a digital Quality Management System (QMS) will often reach for the most familiar tools to build ...
Monitoring and measuring quality of products and services is a key part of any QMS. But how can you be sure th...

Document control is a key part of any Quality Management System (QMS) and, therefore, a requirement of ISO 900...

How do you transform regular supplier reviews from a box-ticking exercise into a genuinely useful commercial a...

What’s wrong with SharePoint, anyway? Why shouldn’t it be used as a document management system (DMS) for a gro...

Does the fertility tracking app you are developing count as a medical device? What about the imaging software ...

ISO 9001 is the internationally recognised standard for quality management used in many sectors from construct...

The PIP scandal, in which thousands of women were injured by faulty breast implants over a period of twenty ye...

How is the quality of your document review process affecting the speed and efficiency of the way you do busine...

We’ve all been there. We’ve lovingly put the final touches to that important document and saved it to the shar...

Question for you: what exactly is a medical device? Is the product you are developing a Medical Device, an In ...

So, you’ve had your brilliant idea. You know what kind of medical device you want to build. You have a vision ...

Having a repeatable procedure for Corrective and Preventive Action (CAPA) is a key FDA requirement for medical...

There are different ways companies can build required quality management systems, from using traditional paper...

What are the planning requirements for a medical device design and development process? And what tools can hel...

WTH is FDA 21 CFR Part 11? That’s a question many medical device developers wanting to access the US market mu...

A focus on a quality management system shouldn’t just mean a ‘box ticking’ exercise for an organisation. And i...

When it comes to medical device development, the absence of comprehensive design and development documentation...

How can medical device developers gain FDA approval for their devices and permission to sell their product int...

%20(1).webp?width=133&height=76&name=ISO%20IEC%2027001%20(1)%20(1).webp)